HBase是一個(gè)基于Hadoop的分布式、面向列的開源數(shù)據(jù)庫,它能夠處理海量數(shù)據(jù),并提供高可靠性、高性能的數(shù)據(jù)存儲(chǔ)與訪問服務(wù)。本文將深入解析HBase的數(shù)據(jù)存儲(chǔ)方式及其請(qǐng)求處理機(jī)制,以闡明其作為數(shù)據(jù)處理與存儲(chǔ)服務(wù)的核心原理。
一、HBase的數(shù)據(jù)存儲(chǔ)方式
HBase的數(shù)據(jù)存儲(chǔ)采用了一種層次化的結(jié)構(gòu),主要包含以下幾個(gè)關(guān)鍵組成部分:
- 表(Table):HBase中的數(shù)據(jù)存儲(chǔ)在表中,表由行和列組成。與關(guān)系型數(shù)據(jù)庫不同,HBase的表是稀疏的,允許動(dòng)態(tài)添加列。
- 行(Row):每一行數(shù)據(jù)由一個(gè)行鍵(Row Key)唯一標(biāo)識(shí)。行鍵是字節(jié)數(shù)組,在表中按字典順序排序,這影響了數(shù)據(jù)的存儲(chǔ)和檢索效率。
- 列族(Column Family):列族是列的集合,在創(chuàng)建表時(shí)預(yù)定義。每個(gè)列族內(nèi)的列可以動(dòng)態(tài)添加,且同一列族的數(shù)據(jù)物理上存儲(chǔ)在一起,這優(yōu)化了存儲(chǔ)和訪問性能。例如,一個(gè)用戶表可能包含“基本信息”和“聯(lián)系信息”兩個(gè)列族。
- 列限定符(Column Qualifier):列族下的具體列,通過列族與列限定符的組合(如“基本信息:姓名”)來唯一標(biāo)識(shí)一個(gè)列。
- 時(shí)間戳(Timestamp):每個(gè)單元格(Cell)可以存儲(chǔ)多個(gè)版本的數(shù)據(jù),時(shí)間戳用于區(qū)分不同版本,默認(rèn)按時(shí)間倒序排列,便于獲取最新數(shù)據(jù)。
- 單元格(Cell):由行鍵、列族、列限定符和時(shí)間戳唯一確定的數(shù)據(jù)單元,存儲(chǔ)實(shí)際的值(Value)。
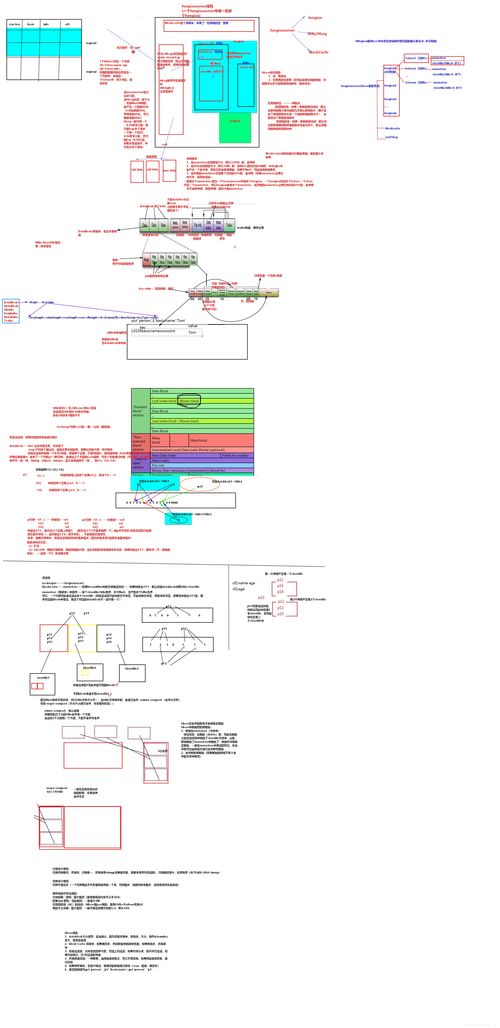
HBase的物理存儲(chǔ)依賴于HDFS(Hadoop Distributed File System),數(shù)據(jù)以HFile格式存儲(chǔ)在HDFS上。表被水平劃分為多個(gè)區(qū)域(Region),每個(gè)Region負(fù)責(zé)表中一段連續(xù)的行鍵范圍。隨著數(shù)據(jù)增長(zhǎng),Region會(huì)自動(dòng)分裂,以實(shí)現(xiàn)負(fù)載均衡。HBase使用MemStore(內(nèi)存存儲(chǔ))緩存新寫入的數(shù)據(jù),定期刷寫(Flush)到磁盤形成HFile,并通過壓縮(Compaction)合并小文件,優(yōu)化讀取性能。
二、HBase的請(qǐng)求處理方式
HBase的請(qǐng)求處理涉及客戶端、主節(jié)點(diǎn)(Master)和區(qū)域服務(wù)器(RegionServer)的協(xié)同工作,主要流程如下:
- 客戶端請(qǐng)求發(fā)起:客戶端通過HBase客戶端API(如Java API)發(fā)起讀寫請(qǐng)求。對(duì)于寫操作,客戶端先將數(shù)據(jù)寫入預(yù)寫日志(WAL)確保持久性,然后存入MemStore;對(duì)于讀操作,客戶端根據(jù)行鍵定位目標(biāo)Region。
- 元數(shù)據(jù)定位:客戶端首先訪問ZooKeeper(分布式協(xié)調(diào)服務(wù))獲取元數(shù)據(jù)表(hbase:meta)的位置。元數(shù)據(jù)表存儲(chǔ)了所有Region的分布信息,包括RegionServer的地址和行鍵范圍。客戶端緩存這些信息,以直接與RegionServer通信,減少元數(shù)據(jù)查詢開銷。
- RegionServer處理:RegionServer是HBase的工作節(jié)點(diǎn),負(fù)責(zé)處理具體的數(shù)據(jù)請(qǐng)求。每個(gè)RegionServer托管多個(gè)Region,并處理以下核心任務(wù):
- 寫請(qǐng)求:數(shù)據(jù)先寫入WAL,然后存入MemStore。當(dāng)MemStore滿時(shí),數(shù)據(jù)刷寫到磁盤形成新的HFile。這種設(shè)計(jì)保證了高吞吐量的寫入性能。
- 讀請(qǐng)求:讀取操作會(huì)同時(shí)查詢MemStore和磁盤上的HFile,通過布隆過濾器(Bloom Filter)快速排除不包含目標(biāo)數(shù)據(jù)的HFile,提高檢索效率。HBase還支持緩存機(jī)制(BlockCache),將頻繁訪問的數(shù)據(jù)塊緩存在內(nèi)存中,加速讀取。
- Region管理:RegionServer監(jiān)控Region的大小,在超過閾值時(shí)觸發(fā)分裂,并定期執(zhí)行壓縮以清理過期數(shù)據(jù)和合并小文件。
- 主節(jié)點(diǎn)協(xié)調(diào):主節(jié)點(diǎn)負(fù)責(zé)集群管理,如Region分配、負(fù)載均衡和故障恢復(fù)。當(dāng)RegionServer失效時(shí),主節(jié)點(diǎn)會(huì)將其上的Region重新分配到其他健康節(jié)點(diǎn),確保服務(wù)高可用性。主節(jié)點(diǎn)本身通常有備份節(jié)點(diǎn),通過ZooKeeper實(shí)現(xiàn)故障轉(zhuǎn)移。
- 數(shù)據(jù)一致性保障:HBase提供強(qiáng)一致性模型。所有讀寫操作都針對(duì)單個(gè)行鍵原子執(zhí)行,客戶端總能讀取到最新寫入的數(shù)據(jù)。通過WAL和分布式鎖機(jī)制,HBase在節(jié)點(diǎn)故障時(shí)也能保證數(shù)據(jù)不丟失。
三、HBase作為數(shù)據(jù)處理與存儲(chǔ)服務(wù)的優(yōu)勢(shì)
HBase的設(shè)計(jì)使其在大數(shù)據(jù)場(chǎng)景下表現(xiàn)出色:
- 高可擴(kuò)展性:通過Region分裂和分布式存儲(chǔ),支持PB級(jí)數(shù)據(jù)水平擴(kuò)展。
- 高性能讀寫:基于LSM樹(Log-Structured Merge Tree)的存儲(chǔ)引擎優(yōu)化了寫入吞吐,而緩存和索引機(jī)制提升了讀取速度。
- 靈活的數(shù)據(jù)模型:面向列的存儲(chǔ)支持稀疏數(shù)據(jù),適合半結(jié)構(gòu)化和非結(jié)構(gòu)化數(shù)據(jù)。
- 強(qiáng)一致性與容錯(cuò):依托HDFS和ZooKeeper,保障數(shù)據(jù)可靠性和服務(wù)連續(xù)性。
HBase通過其獨(dú)特的數(shù)據(jù)存儲(chǔ)結(jié)構(gòu)和高效的請(qǐng)求處理機(jī)制,為大數(shù)據(jù)應(yīng)用提供了強(qiáng)大的數(shù)據(jù)處理與存儲(chǔ)服務(wù)。在實(shí)際應(yīng)用中,如實(shí)時(shí)分析、日志處理和推薦系統(tǒng)等場(chǎng)景,HBase能夠有效管理海量數(shù)據(jù),滿足高并發(fā)訪問需求。理解這些原理有助于開發(fā)者更好地設(shè)計(jì)和優(yōu)化基于HBase的解決方案。